반응형
GMM (Gaussian Mixture Model)
: 특정 데이터의 값이 어떤 분포에 포함될 확률이 더 큰지를 따져서 각 클러스터로 구분하는 게 GMM의 방법론
- 클러스터별로 중심(평균)을 표현하면서 분산의 구조도 함께 띄고 있는 데이터 세트에 효과적
데이터가 원형으로 흩어져 있으면 평균은 있지만 분산이 없는 데이터라고 할 수 있음
→ k-means
데이터가 타원형으로 흩어져 있다면 중심(평균)과 분산의 값을 갖는 형태
→ GMM 모델
특징
특정 분포에 할당된 데이터 수가 적으면 모수 추정이 잘 안됨
정규분포를 따르지 않는 데이터를 다룰 수 없음.
from sklearn.mixture import GaussianMixture
from sklearn.datasets import make_classification
import seaborn as sns
import pandas as pd
%matplotlib inline
# 데이터 생성
X, y = make_classification(n_samples=500, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=6)
df = pd.DataFrame(X)
n_components = 2 # 분포 개수
random_state = 123 # 모델 고정
# 여기에 코드를 작성해주세요
model = GaussianMixture(n_components=n_components, random_state=random_state)
model.fit(df)
df['gmm_label'] = model.predict(df)
# 시각화
sns.set(style="darkgrid")
sns.scatterplot(x=df[0], y=df[1], hue=df['gmm_label'], alpha=0.7, s=100)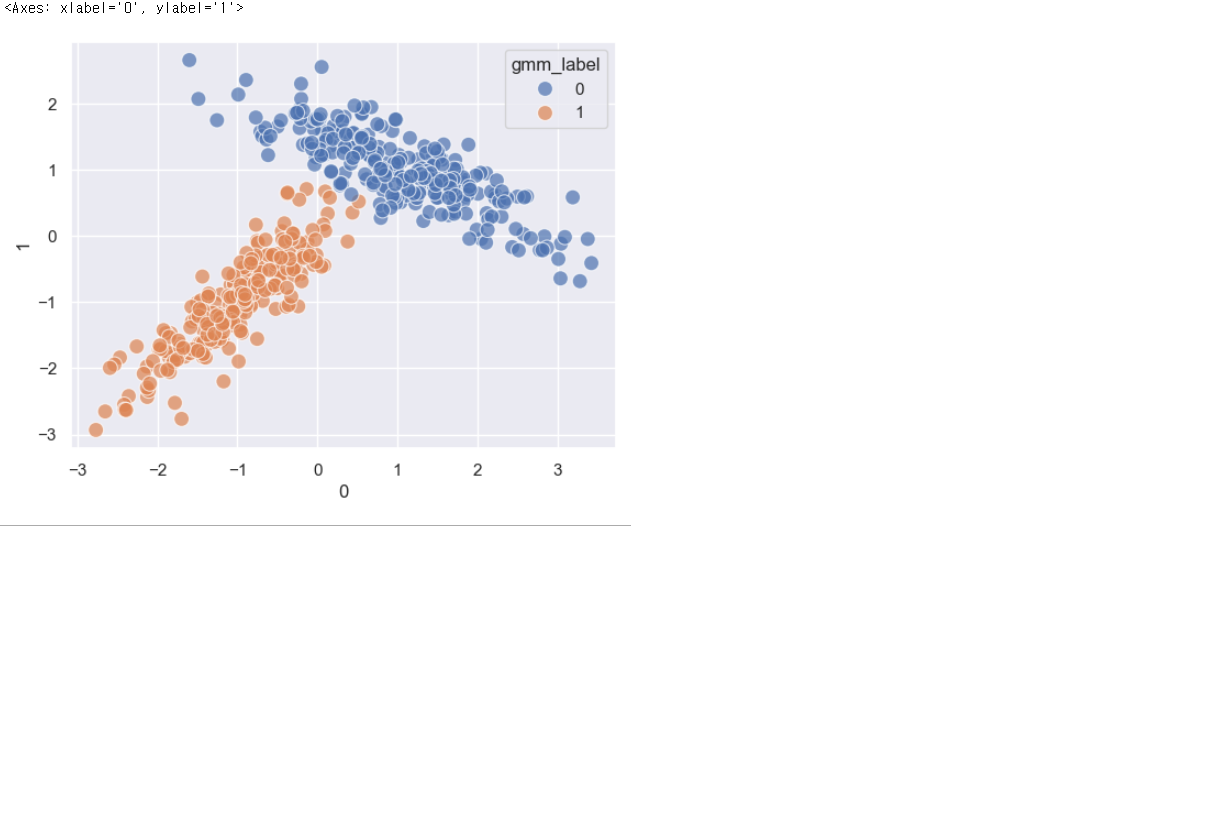
반응형
'Python > DataAnalysis' 카테고리의 다른 글
| [DataAnalysis] PCA(Principal Component Analysis) (4) | 2024.02.07 |
|---|---|
| [DataAnalysis] 차원축소 (0) | 2024.02.07 |